
138-1663-5223





域名、网站、空间、邮箱、推广、400电话、服务器、小程序,完善的产品满足您的公司所需
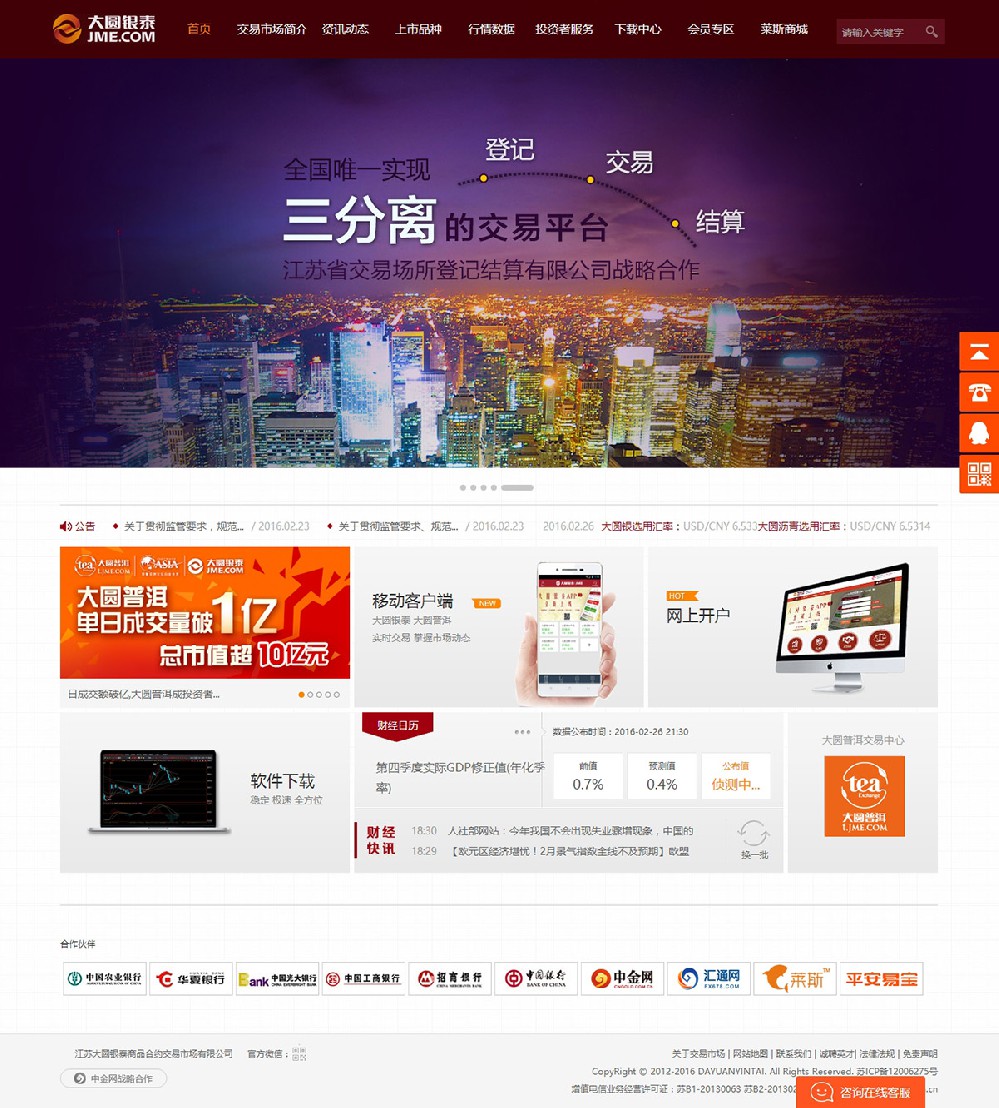
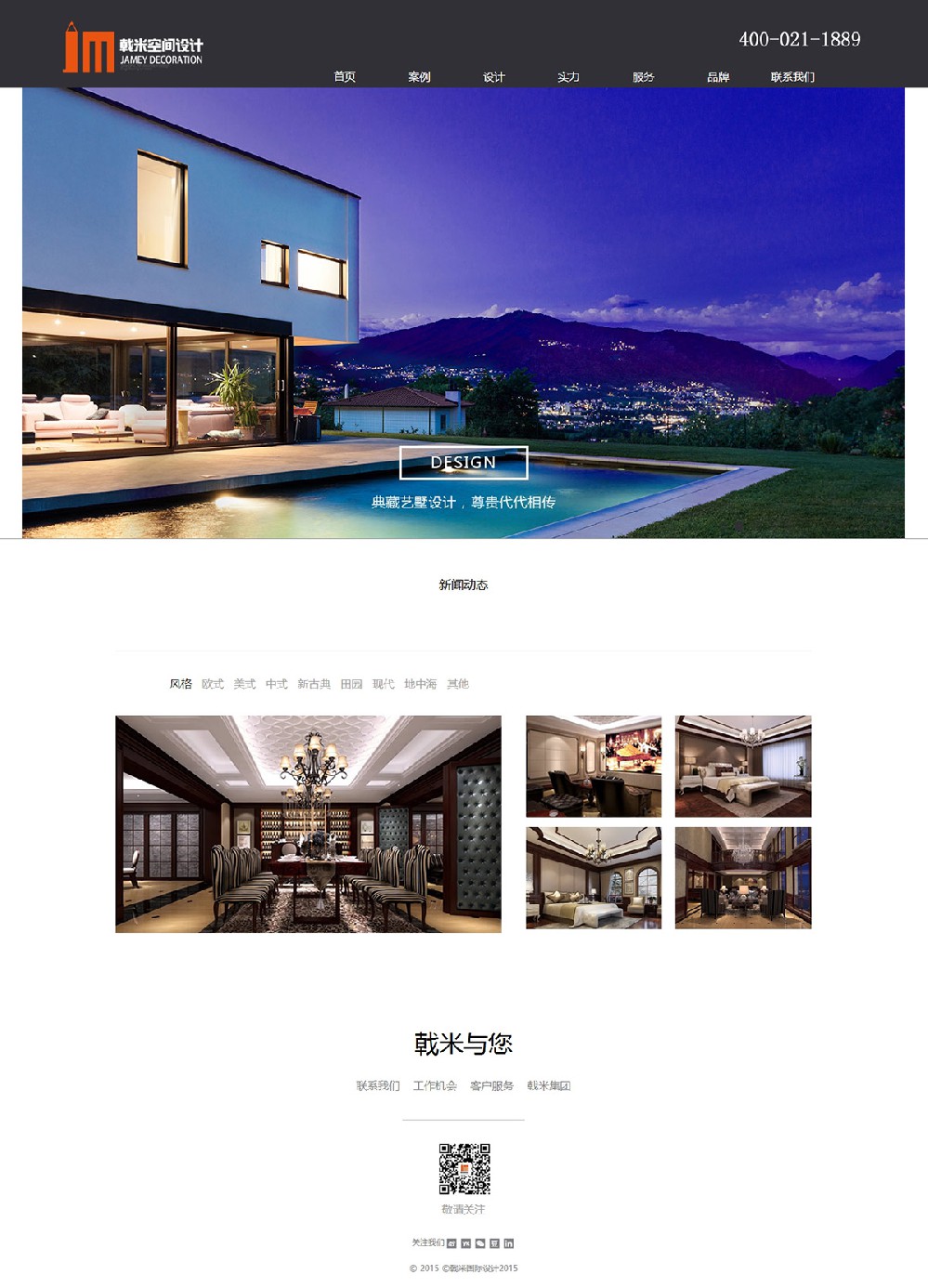
优秀的网站是企业的一张名片
【 手机网站/微网站 】
【 响应式网站 】
【 企业官网/商城网站 】
¥6000 /年起
现代人类越来越依赖移动端
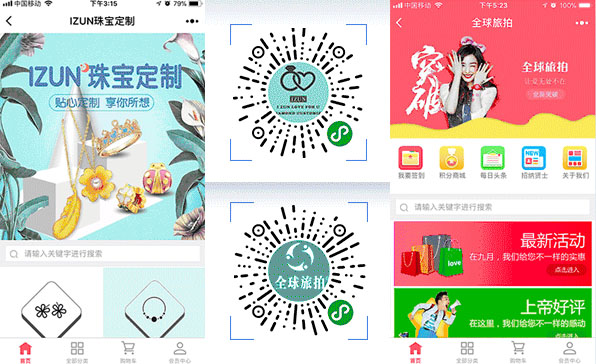
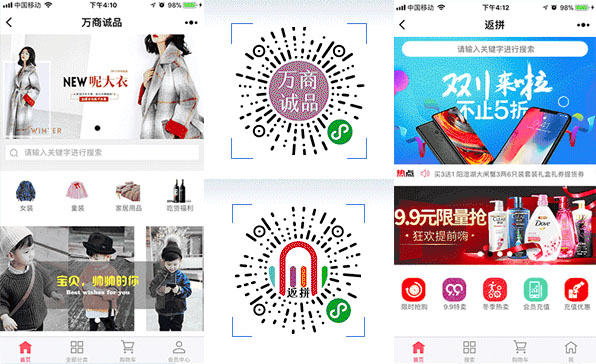
【 手机商城 】
【 APP开发 】
【 小程序商城 】
¥8000 /年起
让更多的关键词获得流量
【 SEO优化 】
【 关键词优化 】
【 百度推广 】
¥90 /月起
域名,空间,邮箱等服务
【 域名/服务器 】
【 400电话 】
【 企业邮箱 】
¥100 /年起
为网站提供安全防护策略
【 服务器安全 】
【 防止SQL注入 】
【 防篡改网站 】
¥800 /年起





互联网前沿技术经验
本地化上门服务
全行业覆盖
客户的认可分数
一对一客户服务
网站建设「一站式」服务商
上海永点网络科技有限公司
成立于 sice 2013
上海永点网络科技有限公司是一家致力于互联网及移动互联网服务的公司,致 力于“微商城、小程序商城、微网站、微信公众号开发、PC商城建设、网站建设、企业邮箱、4···




开通诚信网站

开通可信网站

开通认证联盟

开通安全联盟

开通百度认证

开通服务器证书

开通iTrust网信

开通企业信用评级
欢迎联系我们,我们愿意为您解答任何有关网站疑难问题!
立即咨询获取最新优惠
主营项目:网站建设,手机网站,响应式网站,SEO优化,小程序开发,400电话,企业邮箱等
活动咨询电话:138-1663-5223我们刚刚加推新的双11活动,请立即获取最新报价!






